How It Works
How the Inference Engine Works
The dispatcher routes your request based on --test.
Each test:
- Has defined input requirements
- Applies correct statistical assumptions
- Returns structured output
- Can auto-reroute if assumptions fail
Test Selection Guide
Command Selection Table
| Goal | Command | Required arguments | Notes |
|---|---|---|---|
| Pearson correlation with CI | --test correlation |
--x one_column --y outcome |
Uses Fisher Z CI; tune CI with --alpha. |
| Spearman rank correlation | --test corr-spearman |
--x one_column --y outcome |
Use for monotonic or ordinal relationships. |
| Lagged Pearson correlation | --test corr-lag |
--x predictor --y shifted_outcome |
--lag shifts y before computing Pearson r. |
| Correlation matrix | --test corr-matrix |
--x col1 col2 col3 |
Optional --correction bonferroni|holm|bh applies to matrix p-values. |
| Independent two-group comparison | --test ttest |
--y outcome --group category |
With --auto-route, uses Welch for unequal variance and Mann-Whitney for non-normal samples. |
| Bayesian two-group comparison | --test bayes-ttest |
--y outcome --group category |
Reports BF10 as evidence for the alternative over the null. |
| Paired before/after comparison | --test paired-ttest |
--x before after |
Reports paired t-test, Cohen’s dz, and mean-difference CI. |
| Three or more group means | --test anova |
--y outcome --group category |
With --auto-route, uses Kruskal for non-normal groups and Welch ANOVA for unequal variances. |
| Tukey posthoc comparisons | --test anova-posthoc |
--y outcome --group category |
Tukey HSD controls family-wise error; optional extra correction adds p_corrected. |
| Linear regression | --test ols |
--y outcome --x predictors... |
Supports categorical predictors, interactions, HC3 robust covariance, and bootstrap CIs. |
| Mixed-effects model | --test mixed |
--y outcome --x predictors... --group subject |
Builds y ~ x1 + x2 with random intercepts by --group. |
| Nonparametric two-group test | --test mannwhitney |
--y outcome --group category |
Alternative to independent t-test for ordinal or non-normal data. |
| Nonparametric 3+ group test | --test kruskal |
--y outcome --group category |
Reports epsilon-squared effect size. |
| Mean confidence interval | --test ci-mean |
--y outcome |
Uses t-distribution. |
| Proportion confidence interval | --test ci-proportion |
--y binary_column |
Uses a Wald interval; best for large samples away from 0/1 extremes. |
| Mean-difference confidence interval | --test ci-diff |
--y outcome --group category |
Requires exactly two groups; uses Welch degrees of freedom. |
Correlation Tests
| Test | When to Use | Command Example |
|---|---|---|
correlation |
Linear relationship between two continuous variables | --test correlation --x height --y weight |
corr-spearman |
Monotonic relationship (non-normal data) | --test corr-spearman --x rank --y score |
corr-lag |
Time-shifted correlation | --test corr-lag --x sales --y revenue --lag 2 |
corr-matrix |
Multiple variable correlation overview | --test corr-matrix --x col1 col2 col3 |
Pearson CI uses Fisher Z-transform.
Example:
indexly infer-csv health.csv --test correlation --x cholesterol --y age --use-raw
indexly infer-csv survey.csv --test corr-matrix --x sleep steps mets --correction bh
T-Tests
| Test | When to Use | Required Arguments |
|---|---|---|
ttest |
Compare two independent groups | --y outcome --group category |
paired-ttest |
Same subjects measured twice | --x before after |
Example:
indexly infer-csv trial.csv --test ttest --y blood_pressure --group treatment
indexly infer-csv trial.csv --test ttest --y blood_pressure --group treatment --auto-route
indexly infer-csv trial.csv --test paired-ttest --x before after --bootstrap
indexly infer-csv trial.csv --test bayes-ttest --y blood_pressure --group treatment
ANOVA
| Test | Purpose |
|---|---|
anova |
Compare means across 3+ groups |
anova-posthoc |
Tukey HSD pairwise comparisons |
Supports:
- Assumption checks
- Optional correction (
--correction bonferroni) - Auto rerouting
Routing behavior:
- Non-normal groups with
--auto-route→ Kruskal-Wallis - Normal groups with unequal variance and
--auto-route→ Welch ANOVA - Normal groups with equal variance → classical one-way ANOVA
- Significant classical ANOVA with 3+ groups runs Tukey HSD posthoc automatically
Example:
indexly infer-csv study.csv --test anova --y score --group group_name
indexly infer-csv study.csv --test anova --y score --group group_name --auto-route
indexly infer-csv study.csv --test anova-posthoc --y score --group group_name
Nonparametric Tests
| Test | Alternative To |
|---|---|
mannwhitney |
Independent t-test |
kruskal |
ANOVA |
Use when:
- Data not normal
- Small sample size
- Ordinal variables
Regression
| Test | Description |
|---|---|
ols |
Ordinary Least Squares regression |
mixed |
Mixed-effects model |
Supports:
- Interaction terms
- Bootstrap coefficients
- Assumption validation
Example:
indexly infer-csv dataset.csv --test ols --y outcome --x age income --interaction age income
indexly infer-csv dataset.csv --test ols --y outcome --x age income --bootstrap
indexly infer-csv repeated.csv --test mixed --y score --x week dose --group participant_id
Confidence Intervals
| Test | Description |
|---|---|
ci-mean |
CI for single mean (t-distribution) |
ci-proportion |
CI for binomial proportion |
ci-diff |
CI for mean difference |
Example:
indexly infer-csv survey.csv --test ci-mean --y satisfaction
indexly infer-csv survey.csv --test ci-mean --y satisfaction --alpha 0.01
indexly infer-csv survey.csv --test ci-proportion --y completed
indexly infer-csv trial.csv --test ci-diff --y score --group treatment
Advanced Controls
Auto Rerouting
--auto-route
Automatically switches to a nonparametric test if assumptions fail. For ANOVA, unequal variances route to Welch ANOVA instead of Kruskal when group normality is acceptable.
Bootstrap
--bootstrap
Uses bootstrap confidence intervals where supported.
Multiple Comparison Correction
--correction bonferroni
--correction holm
--correction bh
Applies correction where supported.
For corr-matrix, corrections apply to the pairwise matrix p-values. For anova-posthoc, Tukey HSD already controls family-wise error; an explicit correction adds a conservative p_corrected column.
Output Structure
All tests return a unified structure:
- Statistic
- P-value
- Effect size (when applicable)
- Confidence interval
- Interpretation
- Metadata
- Optional additional tables
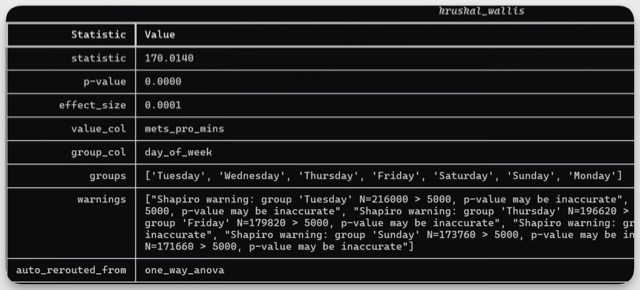
Formatted Inference Output
Summary
The inference engine is:
- Statistically rigorous
- CLI-native
- Assumption-aware
- Modular
- Extensible
You can phrase it like this:
The next section will demonstrate a complete workflow using:
analyze-csvinfer-csv- Report export
If you’d like to understand the statistical concepts behind these commands first, you can review the mathematical foundation section before continuing.